Part 2 of this analysis showed that most words occur quite infrequently and a small number of words are relatively frequent. The few frequently occurring words account for a large portion of all the words, as you can see in the graph below. It shows the cumulative percentage of the words accounted for by the most frequently occurring words.
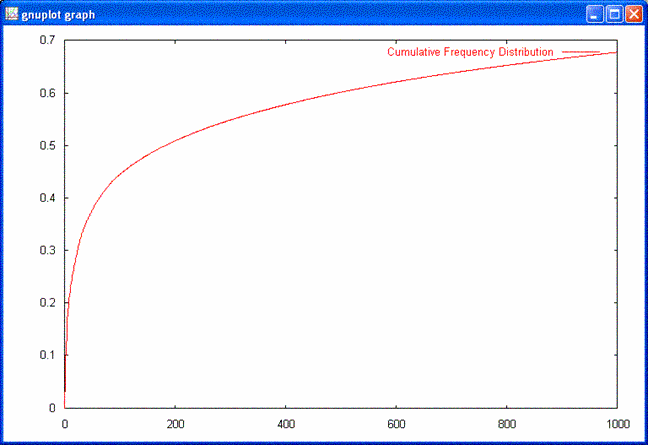
These frequently occurring words are the basis of stopword lists. Typically, they are words like "the" with little content and, because they are so frequent, they provide little assistance in distinguishing one document from another. The following short table helps show this. It gives the percentage of articles in a sample of 19449 articles from the Gigaword corpus that contained some high-frequency words.
Article Word Word Frequency Frequency 0.9961438 0.0602614 the 0.9942928 0.0257411 a 0.9925446 0.0255182 of 0.9917219 0.0239680 and 0.9904365 0.0257643 to 0.9898709 0.0200400 in 0.9793820 0.0096645 for 0.9616947 0.0115454 that 0.9610777 0.0075075 on 0.9536737 0.0093475 is 0.9530053 0.0070007 with 0.9273484 0.0055045 at 0.9249833 0.0048806 by 0.9204586 0.0068690 it 0.9101753 0.0057459 as 0.9057021 0.0049331 but 0.9022572 0.0043638 from 0.8844671 0.0045653 be 0.8811764 0.0038151 an 0.8778858 0.0044713 have 0.8528973 0.0065477 was 0.8447221 0.0038483 not 0.8332048 0.0034692 this 0.8281660 0.0044616 are 0.8277032 0.0039985 has 0.8116613 0.0036878 who 0.7782919 0.0037153 they 0.7766466 0.0069980 he 0.7730989 0.0026451 one 0.7703224 0.0070300 said 0.7546403 0.0025581 more 0.7511954 0.0026859 about 0.7504242 0.0031062 or 0.7375186 0.0024122 when 0.7137642 0.0026925 their 0.6977737 0.0048520 his 0.6977737 0.0028753 had 0.6964883 0.0021471 been 0.6895984 0.0019597 all 0.6864106 0.0019545 which 0.6843540 0.0026721 will 0.6792123 0.0019632 out 0.6751504 0.0019577 up 0.6670266 0.0020536 if 0.6566404 0.0017551 than 0.6553036 0.0022306 were 0.6482081 0.0023275 would 0.6464600 0.0019634 can 0.6420382 0.0022826 new 0.6363823 0.0018479 there 0.6306237 0.0016374 after 0.6257391 0.0015508 other 0.6212659 0.0016070 two 0.6195691 0.0016609 some 0.6151987 0.0042093 i 0.6097486 0.0016481 no 0.6071263 0.0015184 into 0.6067664 0.0016402 so 0.6062008 0.0017226 what 0.6009049 0.0014038 also 0.5857885 0.0016603 like 0.5853771 0.0023522 we 0.5768420 0.0019044 its 0.5692838 0.0027052 you 0.5523677 0.0012331 only 0.5468147 0.0012699 over 0.5462492 0.0013547 just 0.5461977 0.0012781 most 0.5368914 0.0013513 them 0.5282020 0.0012263 now 0.5240372 0.0012460 could 0.5183814 0.0011917 because 0.5170446 0.0012659 do 0.5161705 0.0015190 it's 0.4927246 0.0010803 even 0.4800247 0.0009815 before 0.4730320 0.0010989 many 0.4527739 0.0010287 get 0.4451129 0.0009215 where 0.4412566 0.0009732 how 0.4361664 0.0008930 those 0.4315903 0.0008362 any 0.4305620 0.0009247 then 0.4287110 0.0008520 much 0.4118464 0.0007879 made 0.4094298 0.0007653 while 0.4011517 0.0007986 still 0.4007918 0.0008349 may 0.3958044 0.0012793 him 0.3955473 0.0007786 through 0.3902514 0.0008465 don't 0.3838244 0.0007001 since 0.3803280 0.0007517 off 0.3776544 0.0008254 here 0.3771916 0.0007756 did 0.3750836 0.0007812 good 0.3718957 0.0006986 down 0.3675767 0.0007276 these 0.3674739 0.0006590 another 0.3607383 0.0006532 being 0.3583218 0.0007038 such 0.3579104 0.0007544 going 0.3430511 0.0006440 go 0.3384750 0.0007124 think 0.3327163 0.0006651 very 0.3298884 0.0007119 against 0.3270091 0.0007656 our 0.3263921 0.0006019 too 0.3212504 0.0010430 my 0.3195023 0.0005727 both 0.3187310 0.0019988 she 0.3174456 0.0006180 should 0.3099388 0.0005835 under 0.3093218 0.0005475 between 0.3022778 0.0005501 during 0.2959021 0.0019222 her 0.2838706 0.0007471 me
It seemed surprising that not all of the articles contained "the". A check of the source data showed that the Gigaword data contains a number of anomalous "articles". Some were in Spanish; some were short test messages not intended to appear in print. Some were "The quote of the day" which contained only one sentence. There were no full news articles that did not contain "the".
Also notice that even the least frequent of these words "me" is in 28% of the articles. These words both have little content and do not help to distinguish between documents.